In our paper just published in Trends in Ecology and Evolution, my co-authors Professor Hugh Possingham, Dr Suzanne Prober, and Professor Richard Hobbs and I present a conceptual framework of enigmatic ecological impacts: impacts that tend to pass under the radar of impact evaluations, and evade being considered in environmental impact assessments, offset calculations, and conservation or land-use plans. The problem with these impacts is that they undermine the potential for successful impact mitigation.
For example, a government agency might allow a mining operation to go ahead based on the information provided in the environmental impact assessment that states that the total environmental impact of the mine consists of clearing a given amount of natural vegetation and pumping a given amount of groundwater into a nearby wetland. The agency might consider that in fact the area that the proponent proposes to clear is only 0.001% of the total amount of vegetation, and the groundwater to be pumped is also relatively little in the grand scheme of things, and give approval for the mine to go ahead. However, there are a suite of ways in which the natural environment may be negatively affected that go far beyond the impacts identified in the impact assessment, and ultimately these ‘hidden’ or ‘enigmatic’ impacts may lead to much more environmental degradation that what the agency fathomed.
There are a plethora of different types of ecological impacts that are not systematically accounted for in impact evaluations. We’ve classified them into categories based on the ways in which they tend to get overlooked, but note that whether any particular impact fits into a category depends on its context. I’ll illustrate them with annotated sketches.
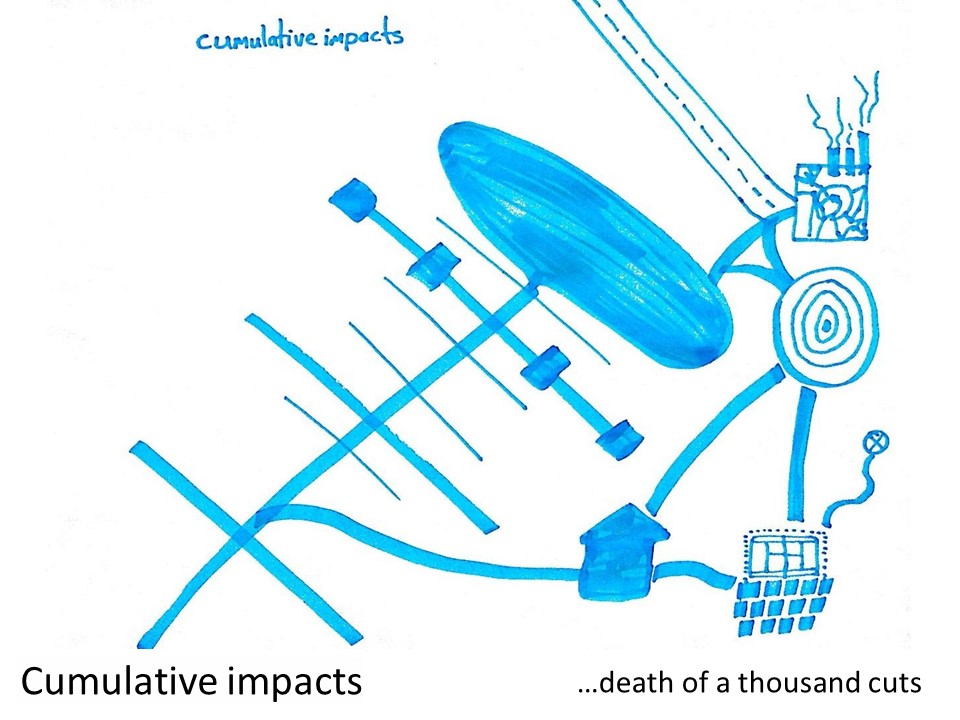
Cumulative impacts: death by a thousand cuts
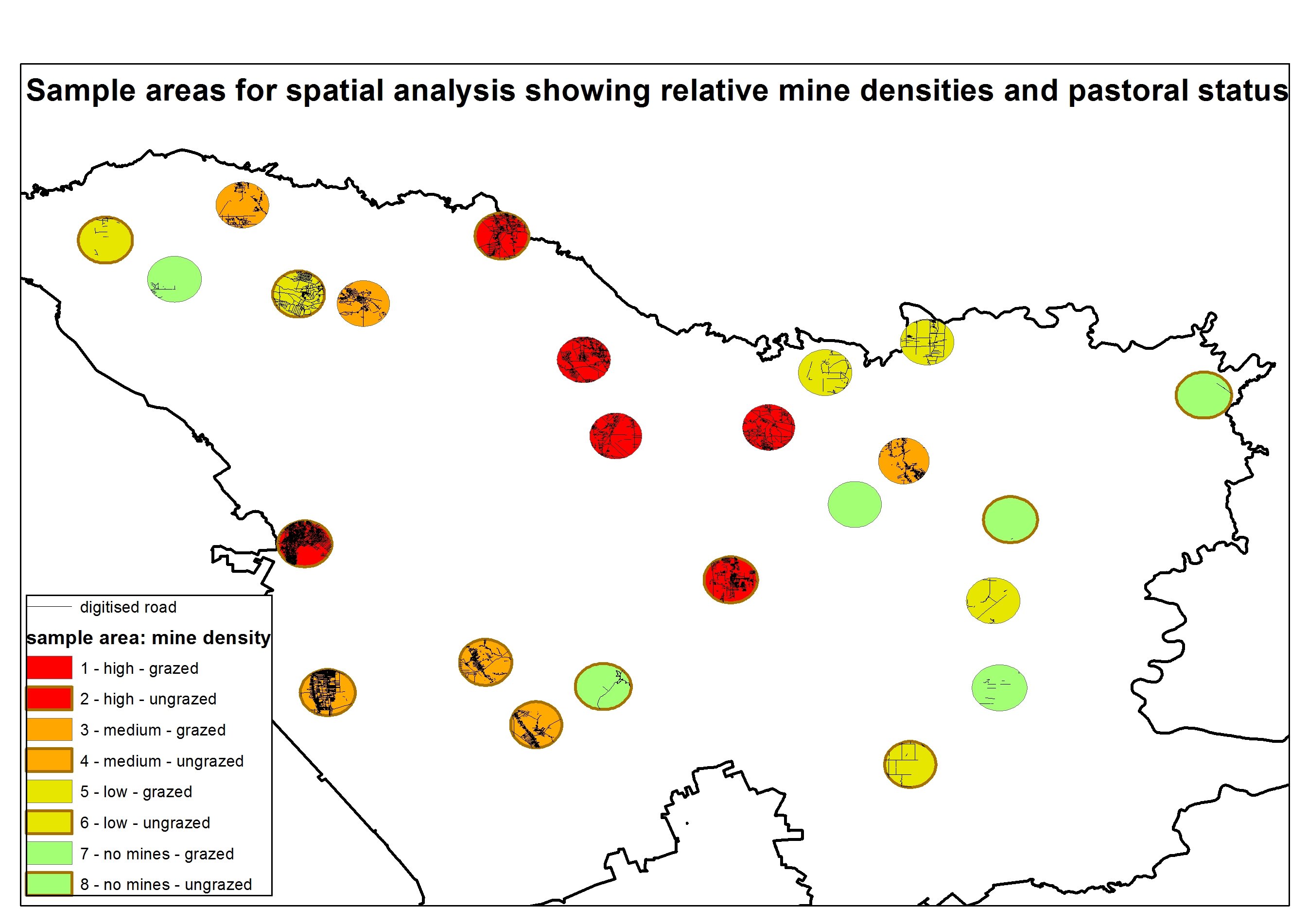
The first category of enigmatic impacts refers to the sum of individual impacts that alone are considered negligible, but accumulate over space and/or time and are so numerous that they are significant when considered in totality. Like eating one small block of chocolate will probably not kill you, but eating thousands each day will certainly lead to severe health complications. In the example of a mining operation, the direct footprint of the mine might be made up of exploration gridlines and access roads, drill pads, mining pit, administration offices, a mine workers village, possibly a processing plant and tailings storage facility, and haul road (Figure 1)…

Now this operation is pretty big, especially when we’re talking about mine pits that are kilometres wide and deep and waste rock dumps that are even wider, but often these operations appear quite small, and even negligible, relative to the region they are in or the amount of vegetation that is left:

That is, until you consider the fact that there are hundreds if not thousands of these types of impact across the landscape, and little is done to account for the cumulative effects of these multiple disturbances…

This is an issue all around the world.

We next see that cumulative impacts are just the beginning of the story. In reality the disturbance doesn’t end at the edge of the obvious disturbance footprint. Offsite impacts are those that are overlooked because they are outside of the immediate location of the development, the designated project area or jurisdiction.

For example, threatened woodland caribous in Alberta, Canada, avoid roads and drill pads by 1km, and that roads further fragment habitat by acting as semi-permeable barriers to movement. With the growth of roads and well pads as you can see in the image on the right, it’s not hard to imagine how it was projected that oil sand drilling will reduce effective caribou habitat in the region from 43 to 6% of the landbase over the next 20 years.

But wait, there’s more. Cryptic impacts are those that generally pass unaccounted for because available methods, time, technology, scientific and regulatory approaches and resource constraints preclude them from being detected.
They’re hidden impacts, that pass unnoticed because we didn’t look hard enough or didn’t look through the right lenses, or simply weren’t able to pick them up:

The effects of low frequency marine noise on cephalopods is an example of cryptic impacts, recently discovered in Spain. According to the researchers, the kind of low frequency noise that is generated in marine environments all over the world by shipping, fisheries, offshore industries, and naval maneuvers, produces permanent, substantial alterations of the structures responsible for the cephalopod’s sense of balance and position. That equals dead cephalopods and potentially dire consequences for the marine food web worldwide, particularly with increasing marine industries.

Next, secondary impacts are impacts that are not directly caused by the development, but are facilitated by it. Third parties such as four wheel drive clubs and other recreationalists, prospectors, loggers, poachers, graziers, arsonists, land speculators, and even researchers (like me), can gain access to previously inaccessible areas due to a development, and unavoidably some of these will result in their own suite of impacts. Thus they are also sometimes referred to as ‘human invasions’.

A sadenning example of this lies in the central African rainforest, where a newly-built road from Bangui to Bambio in the Central African Republic allowed ivory poachers to access an area that was previously inaccessible. As a result, the forest elephant population in that area declined by 40%. The road may have been regarded as essential to promote much-needed economic development, but we can see that the impact of the road extended far beyond the loss of that slither of vegetation.
And just when you thought things couldn’t get any worse, we must remember that nothing exists in isolation; we are likely to experience multiple synergies between the different impacts, including between historical impacts and those occurring now and in the future.

So this cat’s breakfast of scribbles represents what might remain of a landscape in which 0.01% has been cleared for mining.

So what can we do about these impacts? the answers are not obviously simple, but there is hope.
The difficulty of accounting for enigmatic impacts is not the only hurdle to achieving credible impact evaluations. The effectiveness of many impact evaluations can be undermined by a suite of political and economic constraints including corruption, poor governance, attitudes of governments and regulatory agencies, and persistent weaknesses in rigorous scientific input and meaningful public participation.
Effectively accounting for and mitigating enigmatic ecological impacts to conserve what remains of our incredible natural heritage requires strategic and large-scale evaluation and planning, mechanisms to manage and concentrate impacts in areas that are already disturbed, protect relatively undisturbed areas, and conserve wilderness or intactness. It also requires governments, development proponents, and other stakeholders to address historical impacts, mitigate co-occurring impacts, manage access, and enhance impact evaluation practices by improving ethical and professional scientific practice, integrate available knowledge, precautions, decision-support tools, and projections, and conduct long-term research to establish baselines and early warning indicators. Lastly, governments and proponents must address the triple bottom line by improving transparency and public participation, and developing mechanisms to shift risks from society to the marketplace, such as mandatory environmental insurance schemes.
This has been a short summary of the paper – for further information read the paper itself, available here; email me for a free copy (email address available through the link to the paper).
The images posted in this post are extracted, with some modifications, from talks that I have presented to my lab group and various conferences and workshops during the development of this conceptual framework. I thank the Ecological Restoration and Intervention Ecology research group, headed by my primary supervisor Prof. Richard Hobbs, as well as many others along the way, for feedback that has helped and encouraged me to portray the story with textas and pictures. Further acknowledgements regarding support for this research are included in the paper.